


IIoT Data Architecture Using MQTT and Kafka
What is IIoT Data architecture?
IIoT data architecture refers to the structured framework and processes for handling data within an Industrial Internet of Things (IIoT) system. It involves the collection, storage, processing, and analysis of data generated by industrial devices and sensors to derive valuable insights and support decision-making.
Why do you need an MQTT and Kafka data pipeline?
To understand why you need an MQTT and Kafka data pipeline, we need to frame just how much manufacturing data moves. To do that, let’s compare a typical Industrial IoT scenario with a simple commercial IoT solution.
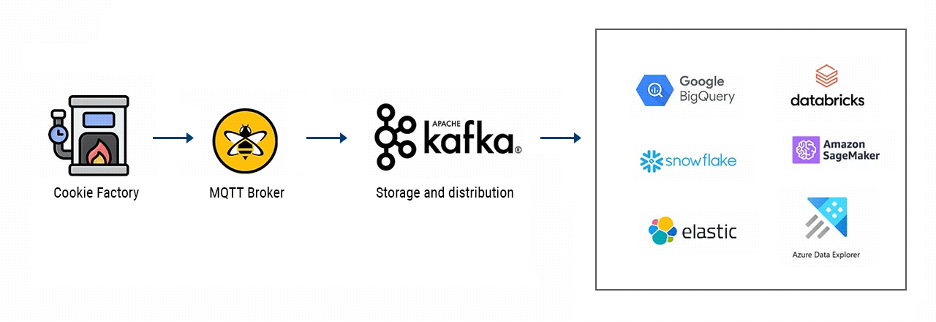
Say you have a vehicle tracking IoT solution; you’d typically read and publish about five to ten data points (such as location, gas level, weight, etc.) every minute. In contrast, if we had a cookie or sweet factory, it is not uncommon to find a furnace with over 1000 measurements that you need to read and process every second. And your cookie factory may have many of these data-intensive furnaces.
When you do the math, you quickly notice that your Industrial IoT solution requires streaming and processing millions of data samples daily. And as your company grows, you need to stream more real-time data will also increase.
So, in the cookie factory example, we need a real-time data infrastructure Industrial IoT solution that persistently processes large volumes of data reliably at scale, making it readily available for enterprise applications. This setup becomes a value-add for the organization. Adding Kafka to the mix will allow us to provide massive amounts of reliable storage and distribution systems with high throughput. It is a buffer for the real-time information streams from your industrial facility. In perfect timing, Kafka feeds these data streams into multiple enterprise applications such as Data Science and Analytics apps.
Comparing MQTT and Apache Kafka for IIoT Data Architecture
However, Kafka is not well suited for structuring communication with Industrial IoT devices and sensors. Contrarily, this is a domain in which MQTT shines. Let us look at a couple of reasons why that is the case.
| MQTT | Apache Kafka |
| Built for constraint devices | Built for data centers |
| Dynamically scales to millions of topics | Can not handle large numbers of topics |
| Default protocol in many IoT devices | No native connection to IoT devices |
| Broker accessed through load balancer | Broker needs to be addressed directly |
| No Keep-Alive or Last Will & Testament |
The role of Kafka vs MQTT
Firstly, Kafka is built for data center environments with stable networks and ‘unlimited’ computing resources. However, IIoT components (devices, sensors, etc.) usually don’t have the luxury of being housed in these resource-rich centers. Instead, they run in harsh environments where network connections are unreliable. Due to its lightweight nature, MQTT is exceptional in resource-constrained settings.
Secondly, Kafka cannot handle large amounts of topics and connected devices. On the other hand, MQTT is built for dynamically scaling hundreds of millions of topics on a single cluster.
Furthermore, most Industrial IoT devices and sensors can’t connect to Kafka natively due to a Kafka client’s resource-intensive and complex requirements.
To compound this difficulty, each broker in a Kafka Cluster needs to be addressed directly. Meanwhile, MQTT broker cluster connects devices to a broker through a load balancer.
One last thing worth mentioning is the fact that Kafka does not deploy crucial delivery features for IoT, such as keep Alive and Last Will and Testament which MQTT implements.
It’s plain to see why the strongest Industrial IoT data pipeline uses MQTT to structure communication with devices and sensors, and Kafka to integrate the data from devices to business applications in a data center. Find out how to avoid data rich, information poor syndrome (DRIP).
More about IIC: Industrial IoT Reference Architecture
FAQs about IIoT Data architecture
What are the 4 stages of IoT architecture?
The four stages of IoT architecture are:
- Sensing: In this stage, IoT devices collect data from the physical world.
- Processing: Data is filtered and analyzed locally or at the edge to reduce the volume of information that needs to be transmitted.
- Transmitting: Processed data is sent to the cloud or other systems for storage and further analysis.
- Acting: Insights from the data trigger actions or decisions, often through applications or control systems.
What is the three-tier architecture of industrial IoT?
The three-tier architecture of industrial IoT consists of three layers:
- Edge Layer: This is where data is collected and processed at or near the source, often on the IoT devices themselves.
- Fog Layer: Additional processing and analysis occur in edge servers, which are closer to the data source than the cloud.
- Cloud Layer: Data is sent to the cloud for storage, further analysis, and access by applications.
This is an excerpt from the Creating IIoT Data Pipeline Using MQTT and Kafka: A Step-By-Step Guide written by Kudzai Manditereza. Access the guide here.

$175K in Non-Equity Funding to Scale Urban Resilience Solutions Globally
As climate change accelerates the frequency and intensity of natural disasters, cities around the world are facing mounting pressure to strengthen their resilience infrastructure. According to the UN Office for Disaster Risk Reduction (UNDRR), the world now experiences an average

Energy-Centric Predictive Maintenance: Smarter, Sustainable Operations for Modern Manufacturers
At Hannover Messe 2025, the evolving role of predictive maintenance takes the spotlight as industrial leaders explore how AI can drive smarter, more sustainable manufacturing. Sunil Vedula, Founder and CEO of Nanoprecise Sci Corp, shares a forward-looking perspective on how maintenance is

The Role of Predictive Maintenance in Achieving World-Class OEE with IIoT
OEE (overall equipment effectiveness) is a productivity and performance metric that helps find new inefficiencies and unlock the full potential of manufacturing. OEE helps manufacturers understand how well a machine, a manufacturing process, or a line is running, as well