


What does it take to work with Generative AI Models
The world of AI is evolving rapidly, and if you’re a machine learning engineer, you might already feel drawn towards generative AI. Generative models are more than just a trend—they represent a leap towards a more creative AI future. But what does it take to transition from traditional machine learning to working with cutting-edge generative models? Let’s explore what this journey looks like and how you can embrace the shift.
Know Your Limits
Before diving into hardware requirements, it’s important to understand the training demands of Large Language Models (LLMs) used by companies like OpenAI, Google, and Meta. These models involve billions of parameters and require vast amounts of computational power, extensive data processing, and optimized infrastructure. The scale of resources needed can be immense, with advanced GPUs, TPUs, and distributed training setups being standard for achieving state-of-the-art performance. To train the largest Llama 3 models, Meta combined three types of parallelization: data parallelization, model parallelization, and pipeline parallelization. The most efficient implementation achieved a compute utilization of over 400 TFLOPS per GPU when trained on 16K GPUs simultaneously.
Phases of LLM Training
LLM training typically involves three key phases, each designed to build and refine the model:
- Pretraining: In this phase, the model learns general language patterns by predicting the next word in a sequence, using massive amounts of text data. This process, known as casual language modeling, allows the model to develop a broad understanding of language.
- Instruction Fine-Tuning: After pretraining, the model is fine-tuned on datasets specific to intended tasks, such as answering questions or summarizing paragraphs. This phase helps adapt the model to particular instructions or objectives, often using ideal answers to enhance its performance for specific applications.
- Reinforcement Learning Fine-Tuning: Finally, the model’s performance is refined using reinforcement learning techniques, which help it align better with user expectations and preferences, often incorporating feedback to improve output quality.
These phases are iterative, often requiring repeated cycles to achieve optimal results. For most users, participating in Phase 1—Pretraining—is not feasible due to the enormous computational power, data, and specialized hardware needed, which are typically accessible only to large organizations or research institutions. However, Phases 2 and 3 are more accessible for users with limited resources. Techniques like changing precision using, PERF or LoRA can help optimize models for efficient use.
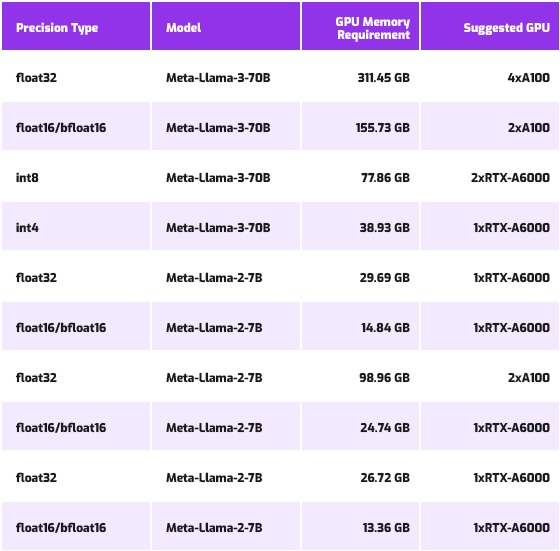
LLAMA modes fine-tuning requirements (Source)
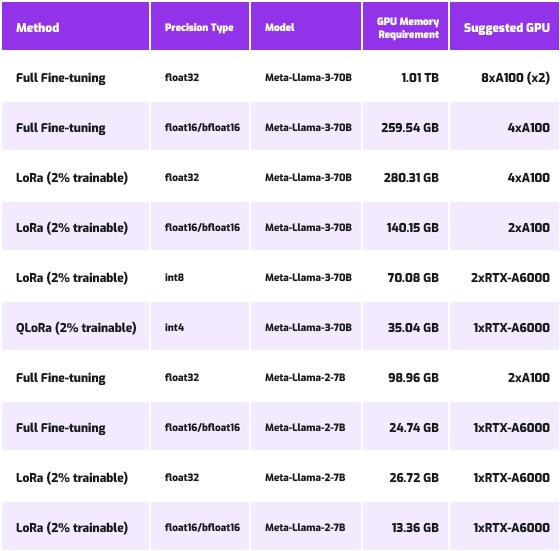
LLAMA modes inference requirements (Source)
Common Computer Vision Models Requirements
Computer vision (CV) is an exciting area of AI, with many popular models used for tasks like image classification, object detection, and segmentation. Some of these models (AlexNet, VGGNet, GoogLeNet, ResNet, EfficientNet) are easy to train on a local PC like, while others, such as Stable Diffusion, are better suited for fine-tuning due to their complexity. In the case of Stable Diffusion, we can create a custom instance of the model that generates images in a specific style. More checkpoints with various styles can be found by following the CIVITAI.

Example of photo styling with different checkpoints — left to right: Original, Crayon style, Mosaic Style, Psychedelic Style, Medieval Style, Chalkboard draw. (Source)
These models serve as a foundation for many computer vision projects and can be fine-tuned or used as a basis for custom solutions. Based on our experiments, we have compiled the following VRAM requirements for some of these models:
VRAM requirements for common CV models
| Model Name | Inference | Training |
| Yolo v8x | 654 MB | 6.6 GB |
| Stable Diffusion XL | 12 GB | 24 GB |
| Unet Plus Plus* | 4.5GB | 10 GB |
| Unet* | 1.2 GB | 4.5 GB |
| Efficientnet v2 m** | 300 MB | 4 GB |
| * For image with size 254*254 pixels and batch size 32
** for image 360 *360 pixels and batch size 6 |
||
Where to Run and Where to Train
We will not focus on free computing instances like Google Colab and Kaggle because, despite providing GPUs for training and running models, they come with significant limitations in terms of runtime and available resources. These platforms are suitable for learning and small-scale projects but are insufficient for more demanding tasks. Instead, we will consider model training and inference options that involve either local devices or cloud services, depending on available resources and model requirements.
Comparison: Custom Local Cluster vs. Cloud Solution
To make a rough comparison between setting up a custom local cluster and using a cloud solution, we will simplify the analysis by focusing only on GPU costs, excluding supplemental costs such as electricity, maintenance, or networking infrastructure.
- Custom Local Cluster: Building a local custom cluster typically involves purchasing high-end GPUs like the NVIDIA A100 or RTX 4090. For instance, an NVIDIA A100 can cost around $10,000 to $15,000 per GPU. Setting up a local cluster with multiple GPUs can lead to a significant upfront investment, but it offers full control over the hardware, which is beneficial for consistent, long-term use without recurring rental fees.
- Cloud Solution: Cloud providers like AWS, Google Cloud, and Azure offer on-demand access to GPUs, typically charging hourly rates. For example, an NVIDIA A100 GPU can cost around $3 to $4 per hour, depending on the provider and region. Cloud solutions are more flexible for short-term needs and eliminate maintenance and upfront costs. However, for extensive training over long periods, the cumulative rental costs can surpass the cost of a custom local cluster.
This comparison highlights that the best choice depends on the duration and frequency of model training. A custom local cluster may be more cost-effective for continuous use, while cloud solutions are ideal for shorter, less frequent tasks.
Average Time for Different Project Types
The time required for a proof of concept (PoC) or a pet project in data science can vary significantly based on factors like project complexity, dataset size, and resource availability. Below are some general estimates:
- Simple Projects (1–2 Weeks): These projects have well-defined goals and readily available datasets, such as exploratory data analysis or simple predictive models. They can typically be completed in 1–2 weeks, covering tasks like data cleaning, feature selection, model building, and evaluation.
- Intermediate Projects (3–6 Weeks): Projects involving larger datasets, multiple data sources, or more complex modeling—such as time-series forecasting or image recognition—can take 3–6 weeks. This timeline allows for thorough data preparation, feature engineering, and hyperparameter tuning.
- Complex Projects (6+ Weeks): High-complexity projects, such as deep learning or natural language processing with custom datasets, often require 6 weeks or more. These projects involve extensive data processing, experimentation, and iteration on model architecture.
These timelines assume a dedicated data scientist or a small team working on the project. If significant work is required for data collection, pre-processing, or stakeholder input, the timelines may extend accordingly.
It is also important to remember that implementing a data science project goes beyond model training. It includes data preparation, organization, and developing or deploying training and inference pipelines. Depending on whether all these steps can be completed on a local device or must be performed directly on a computing instance, the overall cost of using a local cluster versus a cloud environment can be affected.
Our Choice
We choose cloud solutions because they have almost similar maintenance costs but are much more flexible. Cloud solutions do not impose limits on simultaneous usage, are scalable to fit different project sizes, and can be expanded within minutes without waiting for hardware shipments from stores.
Conclusions
It’s important to go beyond using APIs and experimenting with prompt engineering; fine-tuning existing models for specific tasks can significantly enhance their performance and adaptability.
Here are some key points to consider when choosing the right hardware for your experiments:
- Local clusters require significant upfront investment but can be more cost-effective for long-term, consistent use.
- Cloud solutions provide flexibility and scalability, ideal for short-term projects but can accumulate high costs over time.
- The choice depends on specific needs, including training duration, resource availability, and frequency of use.
About the author
Maksym Maiboroda, Junior Data Scientist at Sigma Software Group.

Related articles:

Securing AI at the Edge: Why Trusted Model Updates Are the Next Big Challenge
Recently, customers and partners have been telling us time and again: “I am worried about my expert knowledge being stolen.”, or “My customers expect us to keep their IP safe when we deploy AI agents into operational processes at the

[New booklet] How IIoT and AI Are Driving Smarter Operational Investments
In today’s rapidly evolving industrial landscape, staying competitive means being smart with your operations — and smarter with your investments. Leading organizations are turning to the Industrial Internet of Things (IIoT) and Artificial Intelligence (AI) to optimize processes, cut costs, and boost ROI. This new

AI Copilots: Transforming Manufacturing with Intelligent Assistance
The manufacturing industry is undergoing a technological revolution, with Artificial Intelligence (AI) copilots leading the charge. AI copilots are intelligent assistants designed to work alongside human operators, enhancing efficiency, quality control, and process optimization in manufacturing environments. As industries strive for greater productivity and fewer errors, AI copilots