

The role of the data historian has changed a lot since the 1980s, and it’s time to rethink how it serves us. Industry 4.0 demands better integration between OT and IT systems, allowing teams to centralize data and extract real-time insights across the entire enterprise. But your average data historian is a roadblock. Monolithic, end-to-end data historians weren’t built for this level of flexibility. It’s time to update the ways in which we collect and manage industrial data and it’s time to move beyond the traditional historian model.
The challenges of data historians in industry 4.0
To adopt Industry 4.0 practices, we need an entirely new approach to handling time-series data. Modern industrial systems generate vast amounts of sensor data at increasingly high frequencies. Unfortunately, traditional data historians were not designed to handle this scale or speed.
The main reasons for this are:
- Limited scalability: Most legacy data historians struggle with the growing volumes of data because they were not designed for distributed processing. Rather, they are installed on discrete physical servers that sit close to the source of the data. This prevents them from using cloud-native features such as automated elastic scaling and load balancing.
- High costs: Proprietary data historians come with steep licensing fees, expensive maintenance, and costly renewals. Vendors often impose restrictive pricing structures based on the number of data tags or points collected. Thus, higher data volumes equate to exploding costs.
- Vendor lock-in: Most data historians operate in closed, proprietary ecosystems that limit interoperability. These systems often rely on Windows-based environments and do not support modern, open APIs.
- Lack of real-time processing: Legacy historians are designed for batch processing rather than continuous, real-time data streams. This means they are ill-suited for applications that require instantaneous responses, such as predictive maintenance, anomaly detection, and adaptive automation.
- Rigid query performance: Most traditional historians lack the flexibility required for complex, high-speed queries. They tend to struggle with time-series data due to high cardinality and inefficient indexing mechanisms making queries take longer than necessary.
- Manual data management: With traditional historians, managing data retention, lifecycle policies, and analytics workflows requires significant manual intervention. Data archiving, sharding, and backup processes are not automated, adding overhead for IT and OT teams. The manual nature of these systems makes them prone to human error, increasing the risk of data loss and mismanagement.
Note: If you’re interested in more details about the limitations of legacy data historians, see the article “Are data historians getting in the way of Industry 4.0?” by Mike Rosam (CEO of Quix).
Unbundling the data historian: Quix and InfluxDB
Unlike a proprietary, end-to-end solution, Quix and InfluxDB are two separate tools that complement one another to address the weaknesses of traditional data historians.
- Quix is a telemetry analytics platform that enables you to consolidate high frequency sensor data in a centralized cloud data store, for use cases like real-time monitoring and analytics, predictive maintenance, digital twins, and so on. It was conceived by engineers at McLaren to process high-frequency telemetry from sensors installed in Formula One cars. Quix uses Python as its core language because it’s easy for mechanical engineers to learn and build their own processing applications.
- InfluxDB is a high-performance, time-series database designed for storing, querying, and analyzing time-stamped data, commonly used for metrics, events, and real-time analytics. It was created to overcome the weaknesses of traditional relational databases which struggled with the unique demands of time-series data, such as high write throughput and efficient querying over time windows—which are important features for DevOps monitoring, real-time analytics, and IoT applications.
When used together, Quix can handle the real-time data processing (which most data historians can’t do at all) and InfluxDB can handle the storage and analytics (which it can do far more efficiently than a proprietary data historian).
How does this work in practice? Let’s take a look at a couple of customer examples:
An energy company that needed to do advanced battery monitoring
This company struggled with their traditional plant monitoring systems that provided limited data and lacked granularity. This made it difficult to pinpoint specific issues, especially as their operations grew.
The used Quix together with InfluxDB to build an advanced real time battery monitoring
First, they collected high volumes of high frequency sensor data from batteries at the edge using InfluxDB v1 running on premise . Then, they used Quix to normalize and downsample the data before sinking it to their centralized cloud InfluxDB v3 instance.
This architecture allowed them to collect 1TB of data per day at the same cost they previously incurred for just 300GB and provided them with a wealth of detailed information for analysis.
A manufacturing company that needed to monitor machine health across distributed facilities
A heavy machinery manufacturer wanted to monitor key metrics like temperature, pressure, and motor health of the machines they manufacture. For this purpose, they needed to perform a lot of statistical calculations for which running SQL in a database is not ideal.
They adopted Quix and InfluxDB to effectively collect, process and analyze data coming from their machines in pure Python.
Specifically, Telegraf runs at the edge and transmits data to MQTT. Quix reads from MQTT, pre-processes and analyses the data before sending it to InfluxDB.
Why companies prefer Quix and InfluxDB over a traditional data historian
Customers report that they prefer this combination because both tools are cheap, flexible and easy to use. Most importantly, they both offer features that enable teams to scale their data collection and management without hitting a bottleneck.
For example, both tools come with the following advantages over traditional historians:
Better performance and scalability
Quix and InfluxDB are designed from the ground up to handle high-frequency, high-volume time-series data. Unlike traditional historians, they support distributed processing across multiple servers, high-performance writes AND reads, schema-on-write flexibility, and optimized storage.
Lower Costs with open-source & cloud-native architectures
Legacy historian pricing is prohibitive due to licensing fees and scaling costs. InfluxDB offers an open-source, cloud-native alternative that eliminates expensive vendor lock-in. Combined with Quix, organizations can scale storage dynamically in the cloud and pay only for the storage and compute they actually use.
Real-time stream processing for industrial IoT
Traditional historians store data for later batch analysis. Quix and InfluxDB enable real-time processing with event-driven architectures that respond to events and anomalies detected in live data streams as well as edge-to-cloud integration, which means that systems outside the factory can act on changes in the data.
Open and interoperable
Unlike proprietary historian solutions, the pairing of Quix and InfluxDB offers open APIs that support seamless integration with older systems such as SCADA and OPC servers as well as newer protocols such as MQTT, OPC-UA, and Telegraf for industrial data ingestion.
How Quix and InfluxDB fit into an existing OT/IT architecture
Most industrial systems are multi-layered and divided into OT and IT zones, and separated by a firewalled “DMZ” for enhanced security. However technologies like Quix and InfluxDB are bridging this divide because they can run both on-premise alongside OT systems, and in the cloud, with other IT systems.
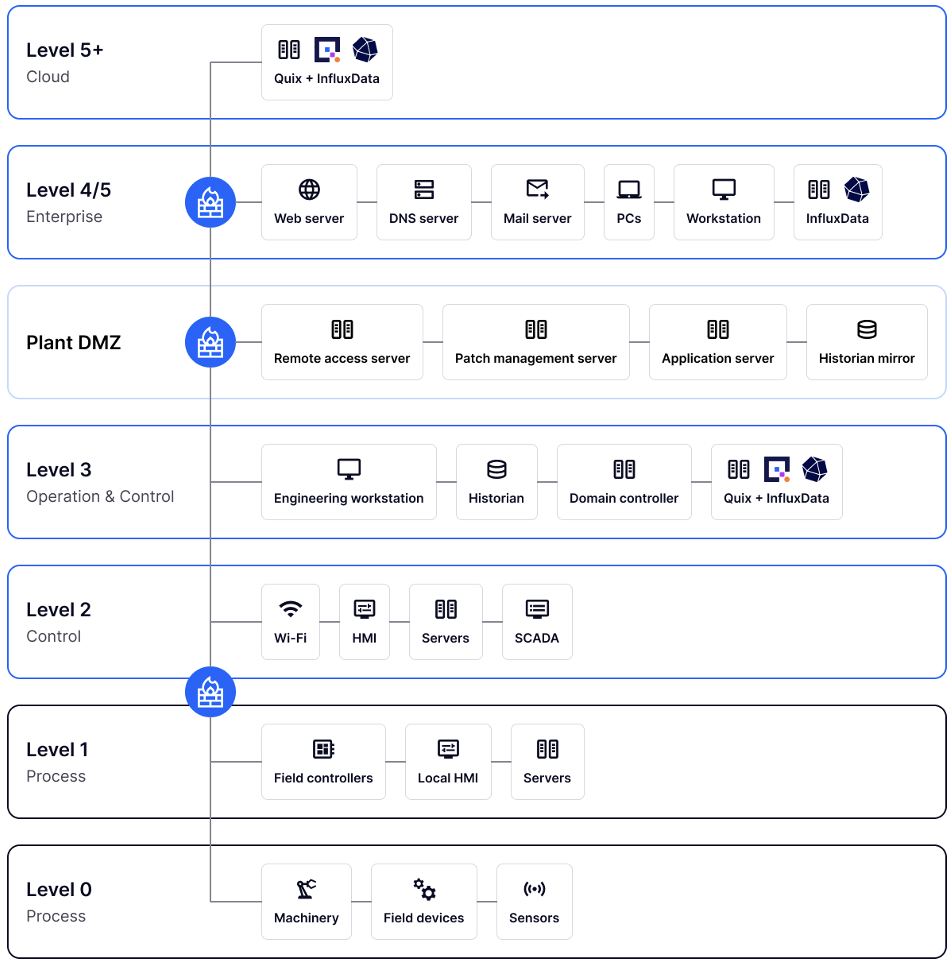
For example, you can run Quix and InfluxDB on-premise, using Quix connectors to read high-frequency data directly from your SCADA system, normalize and downsample it and write it to InfluxDB instances. You can also use Quix to trigger different automations based on patterns detected in the data in real-time.
To consolidate your data enterprise-wide, you can also use Quix to read the data back out of on-premise InfluxDB instances, periodically aggregate and merge it, and write it to another centralized InfluxDB instance (either on your enterprise servers or in the cloud). From there, you can use Quix to perform further transformations and run InfluxDB queries on the transformed data for human analysis or real-time dashboards (in tools like Grafana).
It’s Time to Move Beyond Data Historians
So, are data historians holding you back? If you need to collect more data and gain real-time insights, the answer is likely “yes.” That means it’s time to upgrade to a real-time, scalable, and cost-effective solution built for Industry 4.0.
The idea of change can be daunting—you’re not alone. But modular tools like Quix and InfluxDB make the transition gradual and low-risk. Start small with a pilot project, integrate your existing historian, and scale at your own pace—just as many organizations have done. Once they experience the flexibility and power of Quix and InfluxDB, there’s no turning back. They uncover new use cases beyond the limits of proprietary tools, driving innovation across their operations.
Eventually, the monolithic, end-to-end data historian will be—well, history.


