
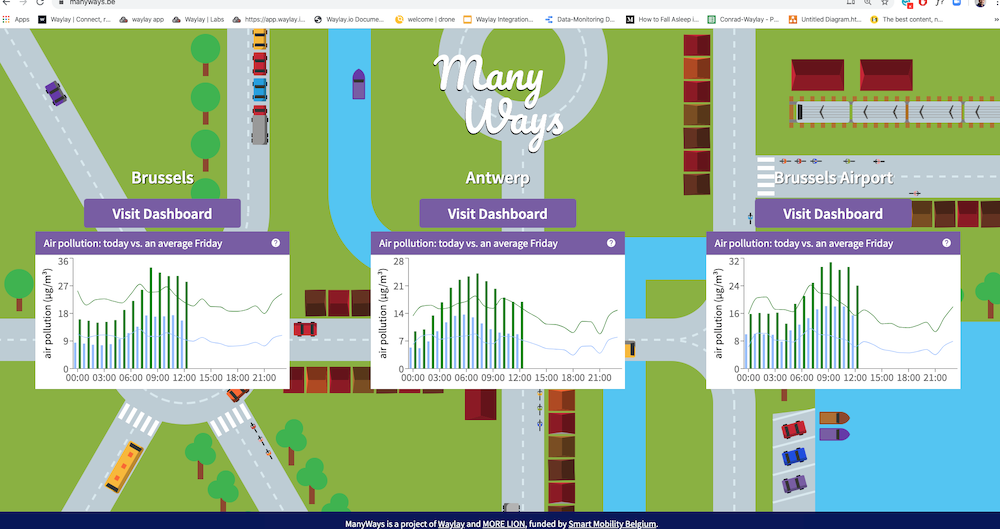
Throughout the whole of last year (2019), we used multiple open data sources to collect data such as highway traffic, air quality, weather, bike rental, car sharing and public transport data, parking space occupancy and much more. It was part of a smart mobility project called ManyWays, that Waylay ran jointly with MORE LION, and which was funded by Smart Mobility Belgium. The project finished at the end of 2019 but we let the ManyWays website, that shows live smart city data for three different areas (the city of Brussels, the city of Antwerp and the Brussels Airport), still run to this day.
One of the reasons we let it run was because this incoming city data served as the perfect test set to verify the AI/ML models for anomaly detection and prediction that we are developing at Waylay for our customer applications.
We started looking for better ways to describe the traffic beyond hourly / daily / weekly patterns, trying to verify exogenous (external) influences, such as weather conditions. We also wanted to check the impact of traffic on the air quality in areas close to the highway. So we kept collecting data in real-time and had the Waylay automation rules engine process the data sets.
The types of challenges that we were trying to solve for our test-city-data are often seen in different real-world applications in energy management, smart buildings or smart HVAC, which are some of our commercial applications, so this was a productive exercise that would also help our customers.
The ManyWays website had been live and public for over 12 months when COVID-19 happened, followed by the lockdown.

Significant traffic drops after the lockdown in Belgium
Belgium declared a lockdown for the entire country over the coronavirus crisis on Wednesday, 18th of March. What you see below is the overall traffic pattern in 2020 for a few selected sections of the highways in Belgium.
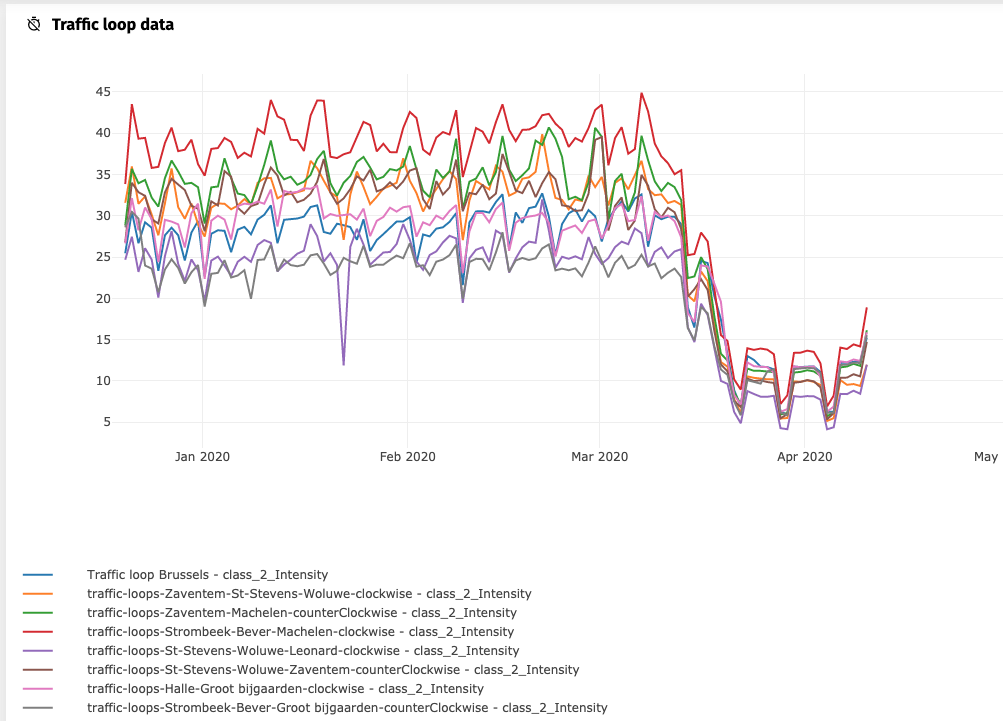
Using the Waylay Dashboard we can zoom into the traffic data set around that time: on March 19th a new lower volume traffic pattern had emerged, with more visible traffic drops over the weekends.
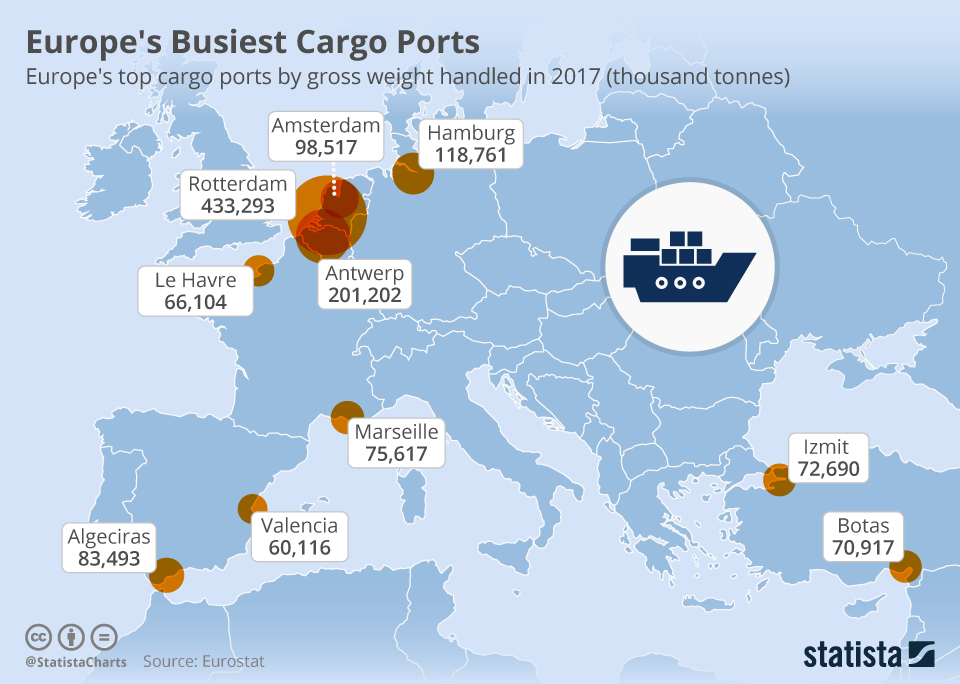
Truck traffic is a good indicator when analysing the impact of COVID-19 measures on international trade. Two of the biggest cargo ports in Europe are Rotterdam and Antwerp, followed by Hamburg and Amsterdam.
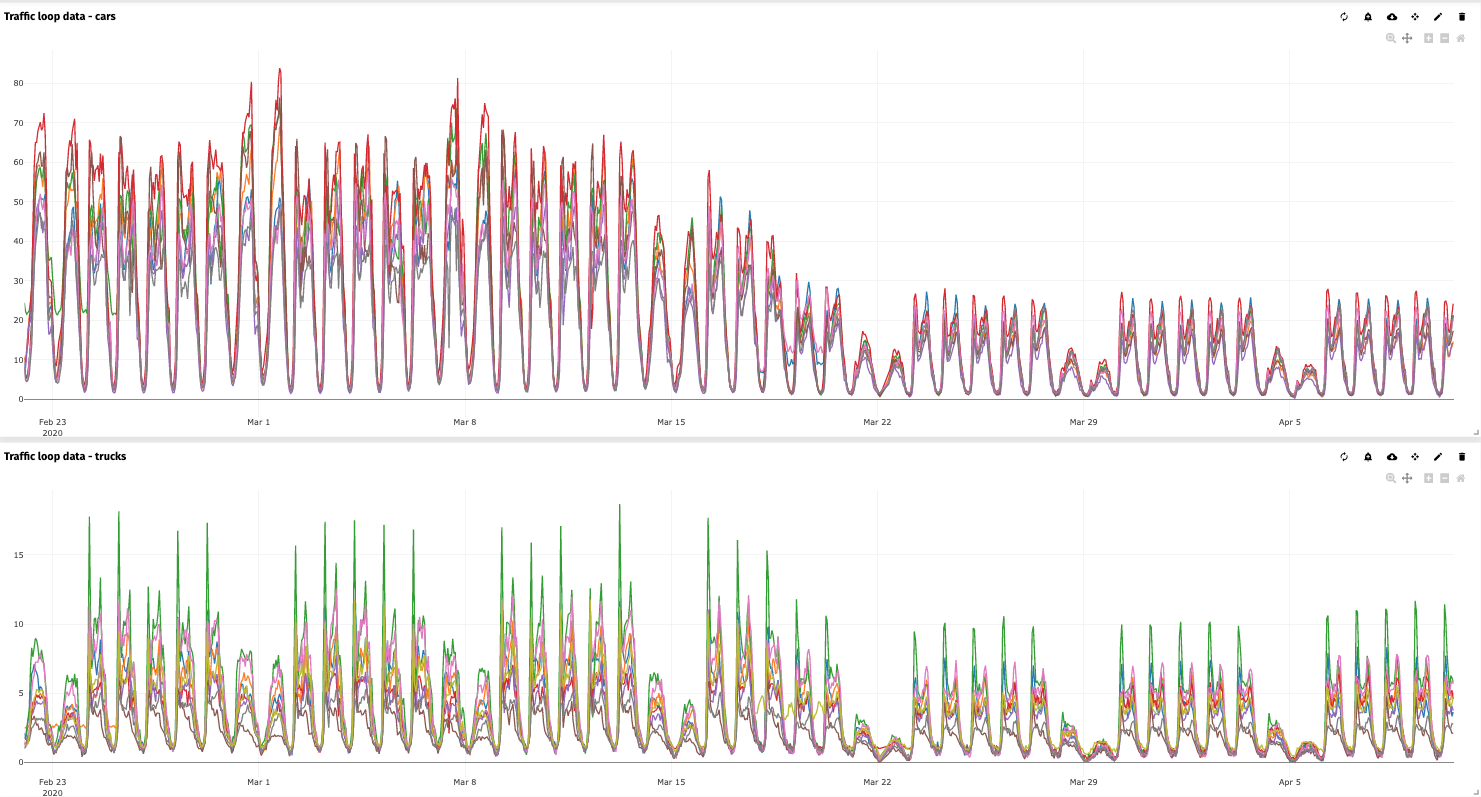
From these ports, most of the transport inland is carried over the highways in Belgium. Looking at the data for trucks, we can see that traffic patterns have not changed that much. Even though the impact of COVID-19 on the overall economy is significant, international transport is still carrying goods around.
No impact on air quality in Belgium, after traffic drops due to lockdown
Since we also capture data from air quality sensors that are placed near highways, we wanted to check if the air quality has improved in any meaningful way over the past weeks. Below you can see some of the locations of the air quality sensors, as shown on the Waylay Dashboard.
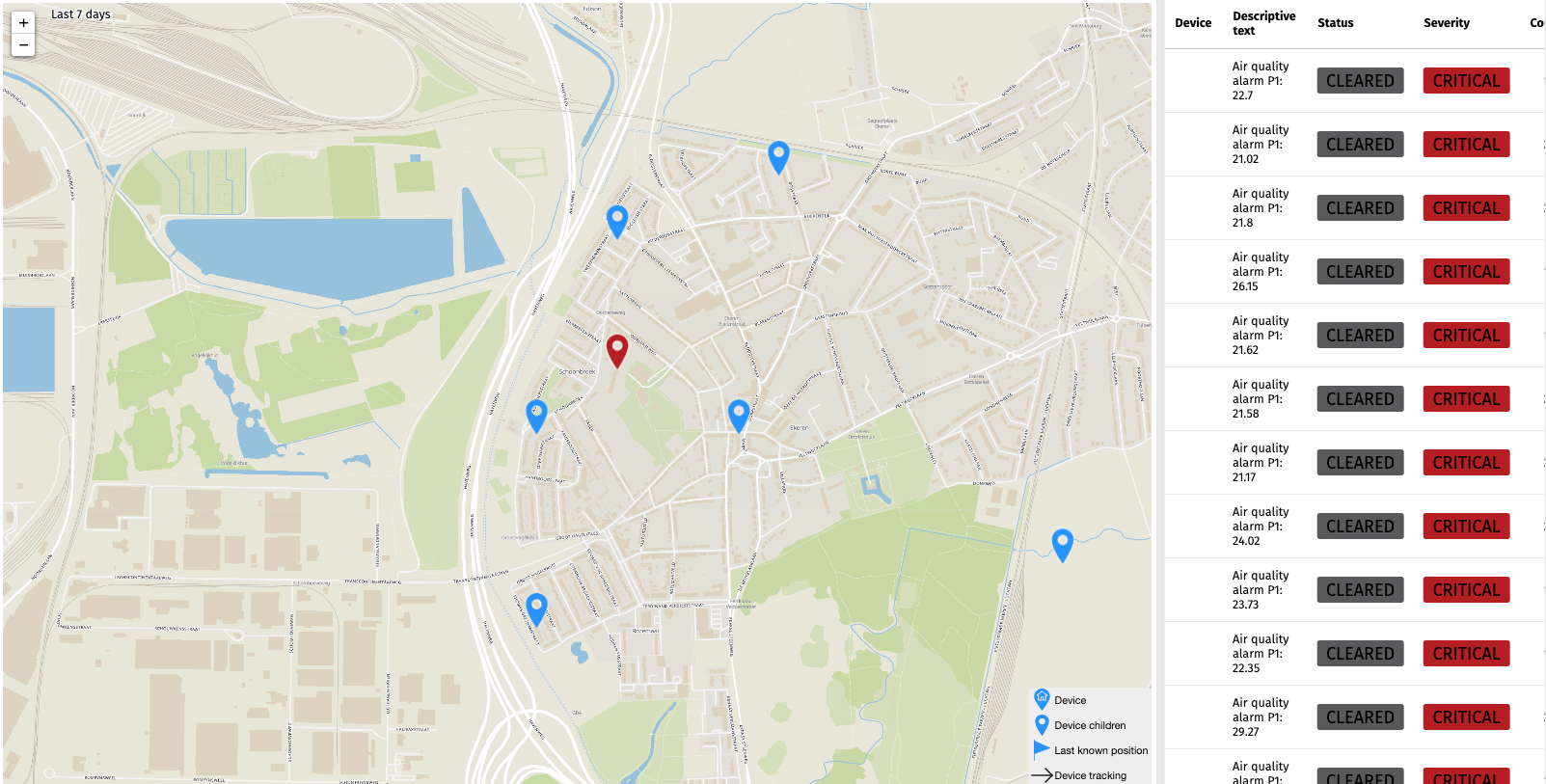
What the data shows is that unfortunately that is not the case, the air quality has not improved. Actually, in some places it showed to be worse than before the lockdown.
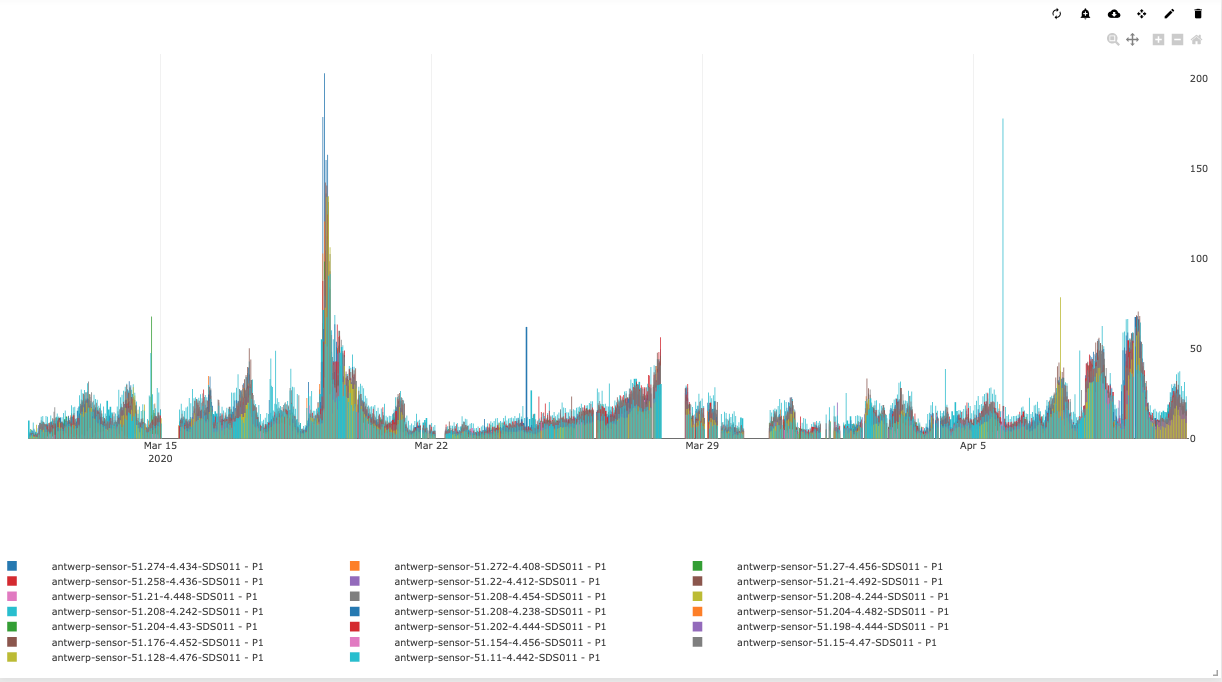
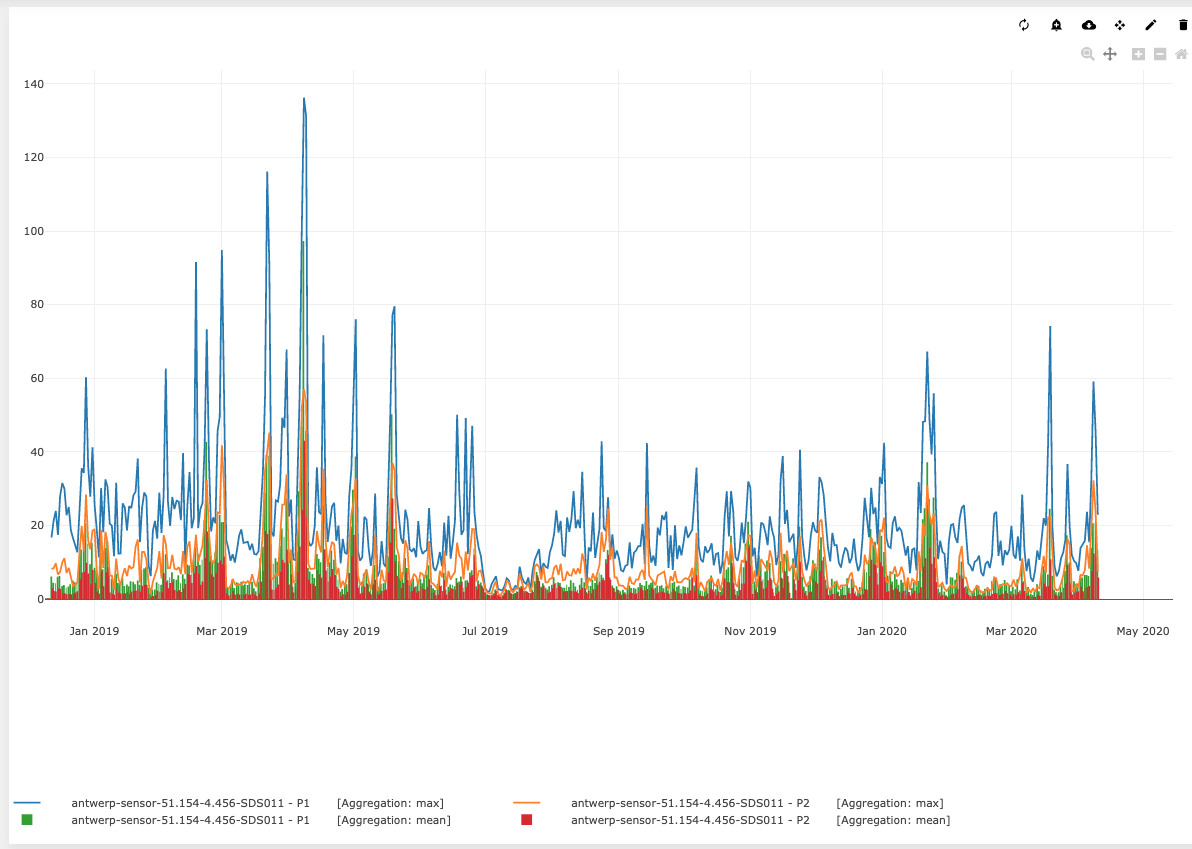
Since this seemed a little counterintuitive, we cross-checked it with the official body that measures air quality in Belgium, IRCEL, and indeed, it turns out to be true.
The graph below shows air quality data over an entire year, and we can see that (for those places at least for which we are collecting data) in 2019 the worst air quality was around March and April as well. And this is generally attributed to other sources of pollution (not road traffic), such as building heating, industry and agriculture.
The role of anomaly detection and prediction models in data analytics
We are often asked by customers, after configuring their automation logic, when should a particular anomaly/prediction model be retrained. This is a good question to try and answer by using the open data on city traffic and air quality that we discussed so far.
But before diving in, let’s see a lightning short definition of these two basic principles, anomaly and prediction.
An anomaly is a deviation in a quantity from its expected value.
When we humans talk about anomalies, we often mean two things:
- something that is an outlier (an outlier = a single data point that differs significantly from other observations)
- something that doesn’t follow a pattern that we expect to see, and patterns require multiple data points, so in this case we talk about expected values (plural) rather than just one single outcome.
A prediction is a statement about the future. It’s basically a guess, albeit based on facts and evidence.
So let’s now take open city data and try to use it to answer the question about model retraining. Below is a graph showing how our anomaly detection and prediction models (configured more than half a year ago) behave against traffic data, for the two weeks after the Belgian lockdown.
In the picture below, blue represents our model’s estimated road traffic, yellow represents our model’s predictions, grey shows the real data and red (almost entirely covering the grey of the real data) shows the model’s identified anomalies in the real data.
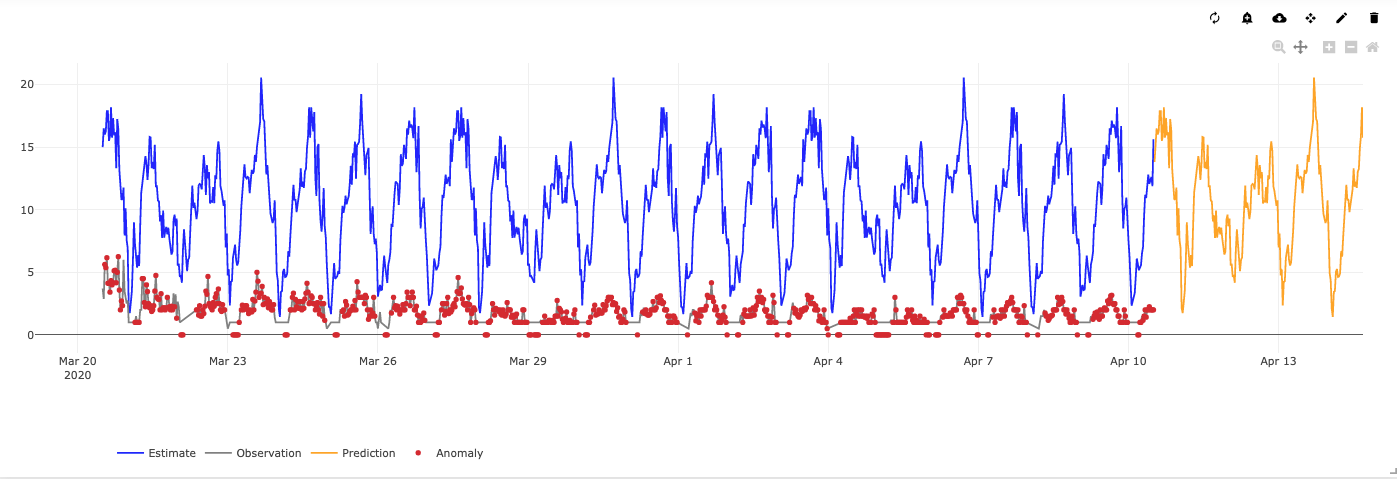
The old models are clearly outdated and all over the place. What does this teach us about retraining? I have two separate answers, one for the prediction model and another one for the anomaly model.
If an analytical model is used for prediction, I often tell customers that it should be retrained as soon as reality is drifting from the norm. For instance, if your model is built to estimate the energy consumption of a particular region or site (in order to guide planning of future energy production) then you constantly want to make sure that the model is matching current observed reality. That means that the model needs to take into account all exogenous influences, such as time of day or time of week (weekday / weekend), outside temperature etc., and apply the right algorithm to predict the future.
There are a number of reasons for a prediction model to fail. It can be either due to poor training data sets used to train the model, failure to account for additional influences, or it can simply be a poor model. If we retrain the models carefully but they still under-perform too often, then we need to take a deeper look into the process to try to either find the variables that were not taken into account or to look for a better algorithm, or both.
When it comes to anomaly detection, we should never automatically retrain the model. Once an anomaly is detected, it requires our attention. It still may be that the model is incorrect, but it’s good to keep in mind that the whole reason we have applied anomaly detection in the first place was to know immediately when an anomaly is registered.
Looking at the graph above that shows how our old model failed the new COVID-19 reality, we pretty much know that traffic patterns won’t change much as long as this situation is not resolved. But I refuse to retrain the old anomaly detection model, because I don’t want to accept this as our new normal.
Let’s hope that the curves are flattened and that we jointly beat this virus, so that our “old model of the future” shows no more anomalies.
Originally this article was published here.
![]() This article was written by Veselin Pizurica, Co-founder and CTO @Waylay, background in telecommunications. Veselin is the author of 12 machine to machine technology patents.
This article was written by Veselin Pizurica, Co-founder and CTO @Waylay, background in telecommunications. Veselin is the author of 12 machine to machine technology patents.


