


DataOps for Manufacturing: A 4-Stage Maturity Model
The promise of Industry 4.0 has many manufacturing leaders thinking big. They envision a future in which real-time access to data opens the door to unprecedented levels of operational flexibility, predictability, and business improvement. For many, early-stage wins often lead to larger projects that stall or fail to scale because their data infrastructure couldn’t support the increasing project complexity.
Enter Industrial DataOps.
DataOps (data operations) is the orchestration of people, processes, and technology to securely deliver trusted, ready-to-use data to all the systems and people who require it. The first known mention of the term “DataOps” came from technology consultant and InformationWeek contributing editor Lenny Liebmann in a 2014 blog post titled, “DataOps: Why Big Data Infrastructure Matters.”
According to Leibmann:
“You can’t simply throw data science over the wall and expect operations to deliver the performance you need in the production environment—any more than you can do the same with application code. That’s why DataOps—the discipline that ensures alignment between data science and infrastructure—is as important to Big Data success as DevOps is to application success.”
DataOps for Manufacturing
DataOps solutions are necessary in manufacturing environments where data must be aggregated from industrial automation assets and systems and then leveraged by business users throughout the company and its supply chain.
HighByte developed a DataOps solution specifically designed for the manufacturing industry that allows manufacturers to create scalable models that standardize and contextualize industrial data. Over the years, we have worked with many manufacturers who are at varying stages of their DataOps implementation and have different goals.
Based on these insights, we’ve created a maturity model to help data leaders at industrial companies understand where they are on their own maturity journey—and where they need to go to achieve the results they expect.
The model defines a four-stage process.
- Data access. The data access stage is generally useful for optimizing controls and other key operational functions. However, many companies find the data is not suitable for higher-level business analytics or most use cases beyond process monitoring.
- Data contextualization. The data contextualization stage provides contextualized and standardized data points to the operations team, enabling them to compare similar data points. The Operational Technology (OT) team benefits by having analytical information they can use to make more informed operating decisions.
- Site visibility. The site visibility stage is focused on providing information payloads to business users outside of operations. This data is typically used to improve quality, research and development, asset maintenance, compliance, supply chain, and more.
- Enterprise visibility. The enterprise visibility stage provides the broadest value to companies, allowing them to aggregate information across sites with common dashboards, metrics, and analytics. It also allows them to implement sophisticated data-driven decision making and Cloud-to-Edge automation.
The successful attainment of each stage—and the benefits associated with them—is dependent on three parameters:
- Team
- Data handling
- Data structure
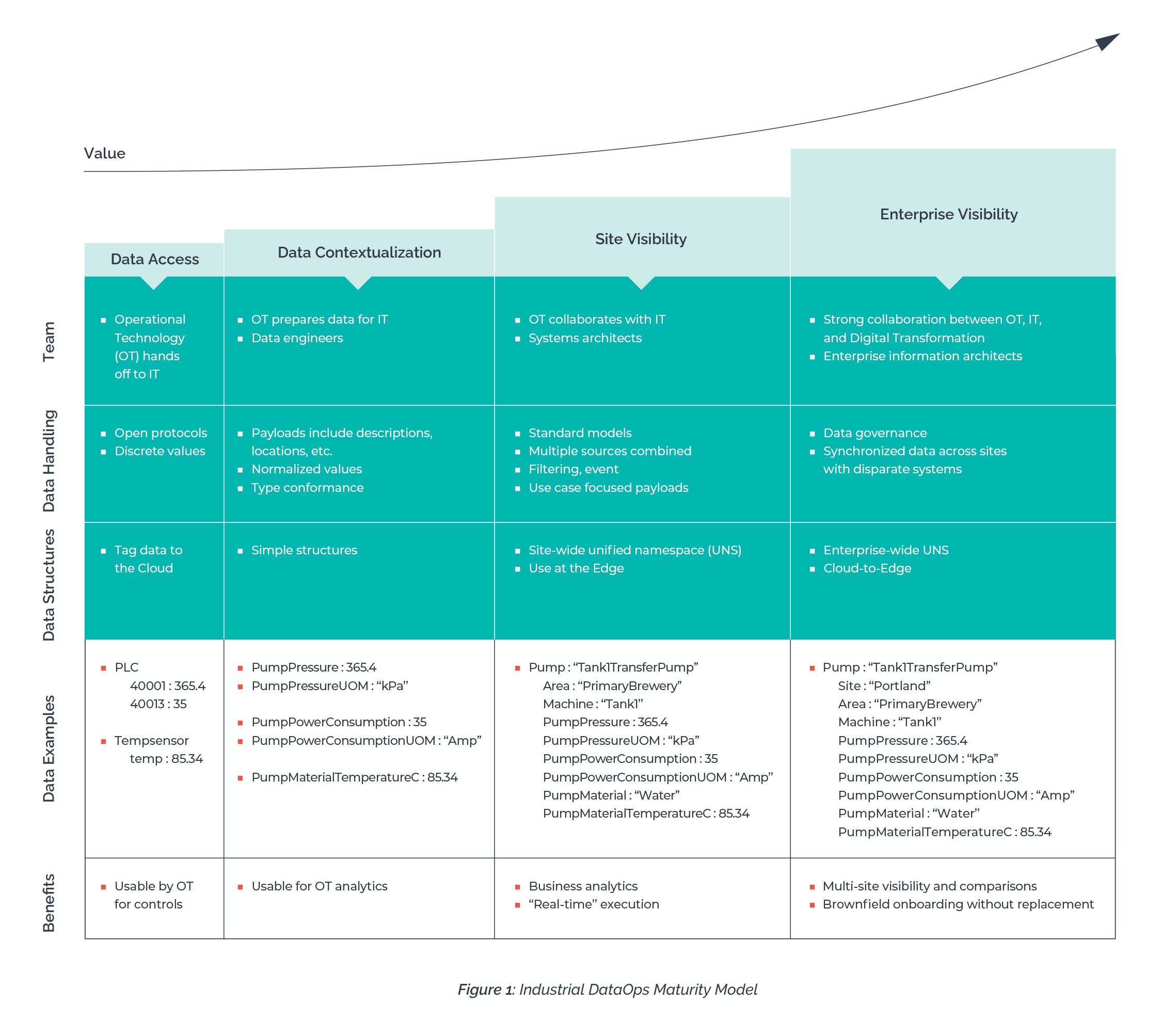
Figure 1 provides an overview of these four maturity stages and how team, data handling, and data structure impact the process. The key takeaway here is that you can’t achieve the benefits of enterprise visibility with the approach of data access.
Many companies have been sold the benefits of enterprise-wide data visibility and usage but do not recognize the data requirements to do so. Business users must work with the teams who support the factory, data must be curated, and solutions must be designed to be implemented at scale across the site and enterprise.
To learn more about this topic, please read the full article.

How AI-Powered Industrial Agents are Transforming Manufacturing Efficiency
Manufacturing is entering a new era of precision and efficiency with the rise of AI-powered industrial agents. These specialized tools are revolutionizing how manufacturers approach problem-solving, decision-making, and operational improvements. By narrowing the scope of AI to specific tasks, industrial

Enhancing Manufacturing Processes with AI and Low-Code: An Essential Guide for Modern Manufacturers
IIoT World’s latest booklet, "Enhancing Manufacturing Processes Through AI and Low-Code Integration," is a must-read resource for manufacturers looking to leverage cutting-edge technologies to drive efficiency, innovation, and productivity. This guide delves into the synergy between AI and low-code platforms, offering actionable

Five reasons why AI projects fail in manufacturing
Implementing AI in manufacturing holds great promise, but the path to success is often littered with obstacles. Despite the hype, many AI projects fail to deliver on their potential. Here are some common reasons why AI projects fail in manufacturing: Data